如果說你問我 各種Microarray 分析中,最困難的是什麼,我會說是 基因網絡分析(Gene network analysis)。這裡基因網絡分析的定義是:研究基因之間交互作用,以及其協同進行生物作用的方法。他跟另一種生物途徑分析(Pathway analysis)意義有些重疊,差別在生物途徑分析的途徑本身是已經確定了基因網路,我們只是分析我們有興趣的基因是否經由這個路徑運作,無法發現新的基因網路。實事上途徑分析的知識來源,其實就是基因網絡分析。在古代基因體科學尚未出現時,生物學家得一個一個基因去研究,才能構建一個基因網絡,那是一個很長的過程,現今那些眾所皆知的生物途徑,幾乎是是累積所有生物學者共同努力的成果,既便是現在,如果能在學術生涯中,能發現一個生物途徑,對生物學家而言,算是非常光榮的成就。
##ReadMore##
到了後基因體時代,我們開始有分析所有基因體的能力, 我們更有機會去分析複雜的基因網路,所以Bioinformatics自開始發展,就不斷被期待著,找到生物分析界的聖杯,解決基因網絡分析的難題。然而,基因網絡分析確始終停留在理論上可行,但實際上所能作的有限的階段。這並不是因為生物資訊研究者偷懶,實在是基因網絡分析的複雜度遠遠超過生物標幟(biomarker)的搜尋這類基礎應用。找生物標幟時,你只要在數萬個基因中找一兩個目標就可以了,但基因網絡分析則要在數萬乘以數萬的基因關係中,到找某幾個基因的組合。以現有的統計工具及數學模型,要解析這樣複雜仍有相當程度的困難,即便真預測到了這樣的組合,要以分子生物方法去驗証,也有相當程度的困難。所以基因網絡分析在"應該可以做"及"現在能做"之間,有很大落差。
在十年前小Lucas覺得網絡分析等待的不是新的量測技術(用 Array or NGS 都一樣),缺的是數學模型及用以解構複雜的適合語言,也許過兩年就可以撥雲見日,但十年過去了,期待中的突破性的發展仍只聞樓梯響, 當客戶們用渴望的眼望看著我,問說可以幫忙做基因網絡分析嗎?可以找出是由什麼基因進行做調控嗎?每每被問到這個問題,我只能尷尬的跟客戶們說,我現在能作的很少,我只能幫你的基因作作Pathway的註解,試著找幾篇文獻幫你把基因連起來,這些註解的工作,没辦法幫你評估這個網絡是否存在,也不能幫你解釋這個網絡跟你關心的事有什麼關係,請你回去多看看 paper,用傳統分子生物的方法去猜測及驗証看看。
那現在的基因網絡分析能做到什麼地步呢?廣意的看大致包括了兩類:第一種是之前提過的生物途徑分析,他是從基因功能組分析(Gene-functional annotation enrichment analysis)延伸而來的,另一類是基因關聯網路,跟我定義的網路分析比較接近,他們通常是利用兩基因間關聯,去連接組合出預測網路。這兩種方法,現在都有不少的工具可以用,但如同前面所說的,目前這些工具還是無法提供準確的預測,原因我們分開來討論:
生物途徑分析(Pathway analysis)
生物途徑分析的原理,與常用的 GO analysis 一樣,把生物途徑中所有基因成員,當作一個基因組(如果一個 GeneOntology 的分類一樣),然後去評估這群基因是否有高於背景值的變異頻率,用以推論生物反應是否跟此生物途徑有關。

一般可以作基因組分析的軟體,通常都可以順便作這樣的預測,我常用的是DAVID,而主流的生物途徑資料庫,通常也會提供這樣的分析功能,例如KEGG、Reactome,你可以從這些軟體中,找到合適生物途徑"註解",用以解釋你所發現基因變化。但這個註解是否正確,我個人郤抱持著懷疑的態度,我不太確定生物途徑可以像GeneOntology 這樣玩基因組分析。因為如同我們知道的,基因組分析很容易受到取樣數及基因組的組成影響分析結果,通常要足夠的取樣數及夠大的基因組,所得到的分析結果才比較可信。然而生物途徑的基因通常很少,而且其中許多調控因子(甚至應該說大部份的調控因子),都是利用表現量以外的方式調節,所以他們在途徑中變動與基因表現無關,所以就在這種取樣少,而且Noise大於 Signal的狀況下,算出來的p 值是否具有參考價值?除此之外,這類分析只能分析你選出來的基因,跟已知的生物途徑有無關係,並不能由基因群本身產生新的知識,預測未知的基因網路,嚴格說來,並不真得符合"基因網絡分析" 的定義,比較像是功能註解。
基因關連網路(Gene conncetion analysis)
基因關連網路分析並不是從已知的生物途徑開始,而是以基因間的關係作為分析單位,在您指定的基因群中,尋找彼此的關連,進而將基因連接成一個基因網絡,這個方法比較接近基因網路分析的概念,因為他可以由零散的基因關係中,去組合出一個新的基因網路。
這類分析方法的基礎是基因-基因關連,如何建置一個完整且正確率高的資料庫,則是成功的關鍵。最常見的基因關連知識的來源,可以從幾個方面獲得,例如大規模的蛋白質分析而來(你可以從這裡找到很多資料)。這些資料庫中蛋白質間的關連,許多是經有間接的方法式取得或根本只是預測,難免有一定比例的錯誤存在,是不是真的還需要更仔細的方法。如果能找到有人曾經花時間設計實驗來驗証過的關連,應該比較可靠,所以何妨就從過去發表的文獻中,去收集學者研究過的基因關係,把他們建成知識資料庫。這種作法生物資訊界有叫作"Text mining",只要寫個程式來自動讀文獻作筆記就好了,例如iHop 就是非常好用的工具。不過說實在的,讀Paper也並不是件容易的事,如果遇到作者英文不好或英文太好時,程式看不懂或誤會了作者的意思,就很產生錯誤的結果,所以text ming 約莫有3%~的錯誤率,要小心不可以太信相他們分析的結果就是了。不過以自動分析為基礎的軟體,資料庫建置成本低,所以相關軟體價格也比較容易讓人親近,甚至有些是免費的。雖然我想有朝一日,程式一定可以更人腦一樣好,解決程式高錯誤率的問題,但現階段也有一個容易方法可以做到,那就是請一堆博士來唸書,作人肉Text ming,這是最好的方法,缺點是博士們的薪水很高,而且他們也有自已的生活,不可能給你一天操二十四小時,所以這種人工建置的關連資料庫,成本非常的高,以之為基礎的軟體,價錢也是天價。

目前已經有許多商用分析軟體,提供基因關連網路分析,例如: IPA, Pathway studio, GeneSpring, GeneGO 等等,因為職務之便,這些一貴松松的軟體,Lucas 都有玩過。但你問我有沒有因為有了這些工具而功力大增?其實也沒有,實事上是失望多於期望,並不是這些軟體不好用,目前基因網路分析還少了很多環節。我們打個比方,看看實際分析上會發生什麼困難:
我們假設真在有一個執行生物功能的基因網路存在,你輸入一群可疑的基因(通常不能太多,不然網路會複雜到無法分析),這些基因很幸運的全部在這個網絡上,更幸運的是這個網路的所有基因關聯全都被發現了,紀錄在資料庫中。這樣足以中樂透的幸運的完美狀態,仍不保証你能劃出這個基因網路,因為如果某些基因交互作用(例如甲基因表現增加,磷酸化乙基因,活化乙基因的作用),會有一個基因表現沒有變化所以沒有被選入,兩基因就不會被連接,少了這些連接存在的網路,就不能變得支離破碎難以辨識。基因迴路涉及太多表現層次以外的關聯,所以很難以用單一技術平台顯現所有關連,因此你只得到一個破碎的網路。在這個案子中你很幸運的可以猜測網絡碎片間關連,還是就有機會把它拼起來,但通常你拿到的是好幾個網路的碎片,絕望的混在一起。
基因網路分析可以利用圖學的方法,補強失落的環節, 例如從一個基因向外延伸,或者找兩基因之間最短途徑,這些手法有助於拼湊破碎的網路,但郤是單憑猜測沒有實驗上的根據,換句話說,你可以用這些方法從任意的兩個基因,無中生有的建構一個以文獻堆砌成的網路,但是不是真的存在,就要看運氣了。
我好像把基因網路分析說的什麼也做不成似的,是的!我的確認為目前在預測新網路上,仍困難重重,這一部份還還在等待許多條件的成熟,實事上基因迴路分析也是 Lucas 基因體分析師的偉大航道上,最重要的課題,這些困難之處我們有些新的觀念及解決的方法, 現在還在蘊釀中,等我們有了初步的結果,再跟大家分享。現階段,我建議不妨從生物途徑分析下手,從已知的生物途徑中,我們還是可以找到許多珍貴訊息,就大部份的"正常"的生物現象而言,其實是很有用的,這些生物途徑都是經過千錘百鍊,被一再驗証的結果, 而且完整的調控網路已定義出大部份的環節了, 基本上你只要把你找到的基因,映對到網路上,看上下游的基因有沒有發生相對映的變化,你甚至可以找到方便的藥物來進行干擾測試。有機會再介紹幾個簡單的方法,從免費的軟體上,不需要花大錢,就可以出美美的圖 。
##ReadMore##
到了後基因體時代,我們開始有分析所有基因體的能力, 我們更有機會去分析複雜的基因網路,所以Bioinformatics自開始發展,就不斷被期待著,找到生物分析界的聖杯,解決基因網絡分析的難題。然而,基因網絡分析確始終停留在理論上可行,但實際上所能作的有限的階段。這並不是因為生物資訊研究者偷懶,實在是基因網絡分析的複雜度遠遠超過生物標幟(biomarker)的搜尋這類基礎應用。找生物標幟時,你只要在數萬個基因中找一兩個目標就可以了,但基因網絡分析則要在數萬乘以數萬的基因關係中,到找某幾個基因的組合。以現有的統計工具及數學模型,要解析這樣複雜仍有相當程度的困難,即便真預測到了這樣的組合,要以分子生物方法去驗証,也有相當程度的困難。所以基因網絡分析在"應該可以做"及"現在能做"之間,有很大落差。
在十年前小Lucas覺得網絡分析等待的不是新的量測技術(用 Array or NGS 都一樣),缺的是數學模型及用以解構複雜的適合語言,也許過兩年就可以撥雲見日,但十年過去了,期待中的突破性的發展仍只聞樓梯響, 當客戶們用渴望的眼望看著我,問說可以幫忙做基因網絡分析嗎?可以找出是由什麼基因進行做調控嗎?每每被問到這個問題,我只能尷尬的跟客戶們說,我現在能作的很少,我只能幫你的基因作作Pathway的註解,試著找幾篇文獻幫你把基因連起來,這些註解的工作,没辦法幫你評估這個網絡是否存在,也不能幫你解釋這個網絡跟你關心的事有什麼關係,請你回去多看看 paper,用傳統分子生物的方法去猜測及驗証看看。
那現在的基因網絡分析能做到什麼地步呢?廣意的看大致包括了兩類:第一種是之前提過的生物途徑分析,他是從基因功能組分析(Gene-functional annotation enrichment analysis)延伸而來的,另一類是基因關聯網路,跟我定義的網路分析比較接近,他們通常是利用兩基因間關聯,去連接組合出預測網路。這兩種方法,現在都有不少的工具可以用,但如同前面所說的,目前這些工具還是無法提供準確的預測,原因我們分開來討論:
生物途徑分析(Pathway analysis)
生物途徑分析的原理,與常用的 GO analysis 一樣,把生物途徑中所有基因成員,當作一個基因組(如果一個 GeneOntology 的分類一樣),然後去評估這群基因是否有高於背景值的變異頻率,用以推論生物反應是否跟此生物途徑有關。
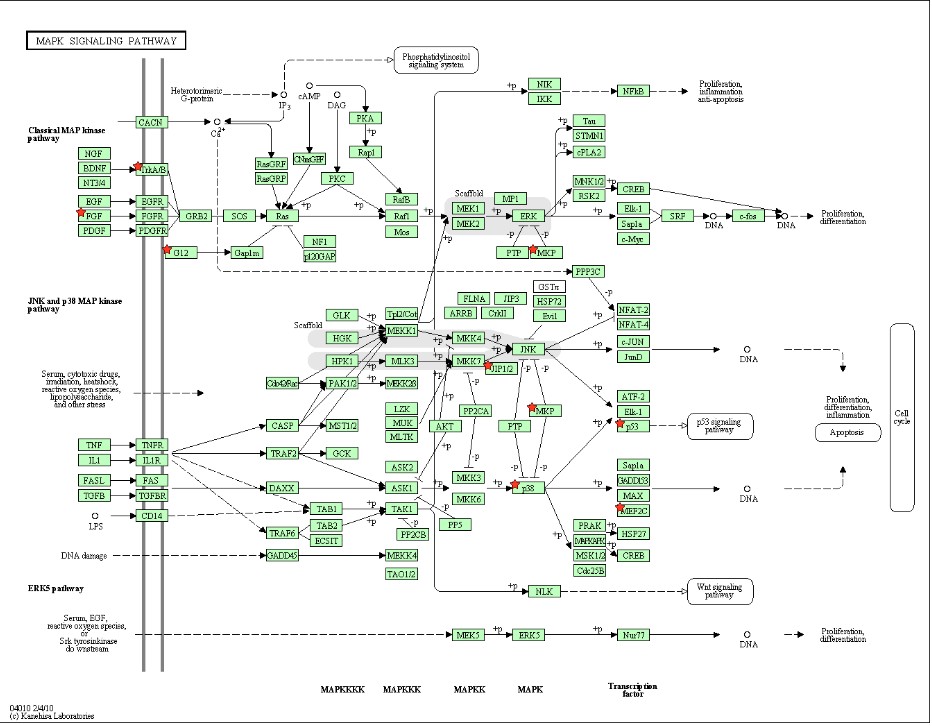
使用DAVID把 Gene list 的基因標示在MAPK signal pathway 中
一般可以作基因組分析的軟體,通常都可以順便作這樣的預測,我常用的是DAVID,而主流的生物途徑資料庫,通常也會提供這樣的分析功能,例如KEGG、Reactome,你可以從這些軟體中,找到合適生物途徑"註解",用以解釋你所發現基因變化。但這個註解是否正確,我個人郤抱持著懷疑的態度,我不太確定生物途徑可以像GeneOntology 這樣玩基因組分析。因為如同我們知道的,基因組分析很容易受到取樣數及基因組的組成影響分析結果,通常要足夠的取樣數及夠大的基因組,所得到的分析結果才比較可信。然而生物途徑的基因通常很少,而且其中許多調控因子(甚至應該說大部份的調控因子),都是利用表現量以外的方式調節,所以他們在途徑中變動與基因表現無關,所以就在這種取樣少,而且Noise大於 Signal的狀況下,算出來的p 值是否具有參考價值?除此之外,這類分析只能分析你選出來的基因,跟已知的生物途徑有無關係,並不能由基因群本身產生新的知識,預測未知的基因網路,嚴格說來,並不真得符合"基因網絡分析" 的定義,比較像是功能註解。
基因關連網路(Gene conncetion analysis)
基因關連網路分析並不是從已知的生物途徑開始,而是以基因間的關係作為分析單位,在您指定的基因群中,尋找彼此的關連,進而將基因連接成一個基因網絡,這個方法比較接近基因網路分析的概念,因為他可以由零散的基因關係中,去組合出一個新的基因網路。
這類分析方法的基礎是基因-基因關連,如何建置一個完整且正確率高的資料庫,則是成功的關鍵。最常見的基因關連知識的來源,可以從幾個方面獲得,例如大規模的蛋白質分析而來(你可以從這裡找到很多資料)。這些資料庫中蛋白質間的關連,許多是經有間接的方法式取得或根本只是預測,難免有一定比例的錯誤存在,是不是真的還需要更仔細的方法。如果能找到有人曾經花時間設計實驗來驗証過的關連,應該比較可靠,所以何妨就從過去發表的文獻中,去收集學者研究過的基因關係,把他們建成知識資料庫。這種作法生物資訊界有叫作"Text mining",只要寫個程式來自動讀文獻作筆記就好了,例如iHop 就是非常好用的工具。不過說實在的,讀Paper也並不是件容易的事,如果遇到作者英文不好或英文太好時,程式看不懂或誤會了作者的意思,就很產生錯誤的結果,所以text ming 約莫有3%~的錯誤率,要小心不可以太信相他們分析的結果就是了。不過以自動分析為基礎的軟體,資料庫建置成本低,所以相關軟體價格也比較容易讓人親近,甚至有些是免費的。雖然我想有朝一日,程式一定可以更人腦一樣好,解決程式高錯誤率的問題,但現階段也有一個容易方法可以做到,那就是請一堆博士來唸書,作人肉Text ming,這是最好的方法,缺點是博士們的薪水很高,而且他們也有自已的生活,不可能給你一天操二十四小時,所以這種人工建置的關連資料庫,成本非常的高,以之為基礎的軟體,價錢也是天價。
由Ingenuity pathway assistant(IPA) 劃出的基因網路
目前已經有許多商用分析軟體,提供基因關連網路分析,例如: IPA, Pathway studio, GeneSpring, GeneGO 等等,因為職務之便,這些一貴松松的軟體,Lucas 都有玩過。但你問我有沒有因為有了這些工具而功力大增?其實也沒有,實事上是失望多於期望,並不是這些軟體不好用,目前基因網路分析還少了很多環節。我們打個比方,看看實際分析上會發生什麼困難:
我們假設真在有一個執行生物功能的基因網路存在,你輸入一群可疑的基因(通常不能太多,不然網路會複雜到無法分析),這些基因很幸運的全部在這個網絡上,更幸運的是這個網路的所有基因關聯全都被發現了,紀錄在資料庫中。這樣足以中樂透的幸運的完美狀態,仍不保証你能劃出這個基因網路,因為如果某些基因交互作用(例如甲基因表現增加,磷酸化乙基因,活化乙基因的作用),會有一個基因表現沒有變化所以沒有被選入,兩基因就不會被連接,少了這些連接存在的網路,就不能變得支離破碎難以辨識。基因迴路涉及太多表現層次以外的關聯,所以很難以用單一技術平台顯現所有關連,因此你只得到一個破碎的網路。在這個案子中你很幸運的可以猜測網絡碎片間關連,還是就有機會把它拼起來,但通常你拿到的是好幾個網路的碎片,絕望的混在一起。
基因網路分析可以利用圖學的方法,補強失落的環節, 例如從一個基因向外延伸,或者找兩基因之間最短途徑,這些手法有助於拼湊破碎的網路,但郤是單憑猜測沒有實驗上的根據,換句話說,你可以用這些方法從任意的兩個基因,無中生有的建構一個以文獻堆砌成的網路,但是不是真的存在,就要看運氣了。
我好像把基因網路分析說的什麼也做不成似的,是的!我的確認為目前在預測新網路上,仍困難重重,這一部份還還在等待許多條件的成熟,實事上基因迴路分析也是 Lucas 基因體分析師的偉大航道上,最重要的課題,這些困難之處我們有些新的觀念及解決的方法, 現在還在蘊釀中,等我們有了初步的結果,再跟大家分享。現階段,我建議不妨從生物途徑分析下手,從已知的生物途徑中,我們還是可以找到許多珍貴訊息,就大部份的"正常"的生物現象而言,其實是很有用的,這些生物途徑都是經過千錘百鍊,被一再驗証的結果, 而且完整的調控網路已定義出大部份的環節了, 基本上你只要把你找到的基因,映對到網路上,看上下游的基因有沒有發生相對映的變化,你甚至可以找到方便的藥物來進行干擾測試。有機會再介紹幾個簡單的方法,從免費的軟體上,不需要花大錢,就可以出美美的圖 。
作者已經移除這則留言。
回覆刪除Hi Lucas,
回覆刪除Thanks for sharing this introduction of gene-network.